The rise of generative AI has opened up new ways for enhanced human-machine collaboration and groundbreaking discoveries. With its power to create new content starting from a prompt, such as images, texts, audio, video, or even other types of data, generative AI has the potential to revolutionize data analysis in many diverse fields.
However, despite being lauded as one of the most beneficial technological advancements in history, AI still hasn’t been widely adopted by organizations. There are three main reasons for this:
Resources: One of the primary barriers to AI adoption is the scarcity of expert users. Data scientists have become increasingly in demand as organizations seek to pull meaningful and actionable insights from the millions of bytes of data they produce each day. However, the data science talent pool is small and even when they do get hired, they’re simply juggling too many competing projects to focus on AI adoption.
Trust: While some still fear the doomsday potential of AI, what’s actually hurting trust in AI is confidence in the results it generates. Adding to that distrust is a lack of knowledge, even at a high level, of the proposed solutions and their implications. Hallucinations, for example, occur when generative AI bots return made-up information, but this issue usually stems from an incomplete query or inaccurate dataset. Without the right data science talent to train the model and help encourage AI adoption, it’s challenging to build up trust in the technology.
Usability: Many existing AI tools are challenging to use, typically requiring specialized knowledge and expertise in data science. Increased adoption requires user-friendly tools that analysts and other non-data science experts can leverage to gain a genuine understanding of complex, multidimensional, and heterogeneous data.
Democratizing AI with Intelligent Data Exploration
It’s clear that the barriers to widespread AI adoption ultimately stem from the scarcity of data science experts. Waiting to hire for these skills risks companies being left behind in the race to analyze enterprise data for business-changing insights. Fortunately, addressing these problems can be achieved through Intelligent Exploration, Explainable AI (XAI), and Large Language Models (LLMs).
An intelligent data exploration platform, such as the one patented by Virtualitics, leverages XAI, Generative AI, and rich visualizations to guide users through the analysis of complex datasets. Low-code or no-code environments that allow users to log in and immediately begin exploring their data for insights are crucial to the adoption of AI inside the organization. Generative AI technology can be used to:
- Use embedded AI routines to generate multidimensional visualizations based on available data and contextual information.
- Deliver key insights in natural language augmented with compelling, AI-generated visualizations.
- Use LLMs to suggest the next steps in the analysis based on user prompts. These prompts can be specific (“I want to understand what drives sales in summer”) or more open-ended (“Tell me something interesting about my data”).
Intelligent exploration leads teams to findings that can be clearly understood, prioritized, and acted upon.
Enabling a Conversational Approach to Data Analysis
Two of the keys to democratizing complex data analysis with Intelligent Exploration are the use of XAI and LLMs.
To be effective, XAI has to strike the right balance between model interpretability and accuracy. It is essential that we do not compromise accuracy while focusing on context-aware explanations, which entails designing explanations that consider the specific context of the analysis conducted.
Additionally, XAI systems must generate explanations suitable for different audiences that don’t require a data expert to interpret them. A few years ago, advancements in Natural Language Processing (NLP) introduced the capability to ask queries using natural language, but these systems faced limitations due to their restricted vocabulary and ad hoc syntax.
LLMs overcome these limitations by presenting results in the form of a narrative, featuring simple language and relevant charts that are generated automatically.
The AI-Friendly Future
Intelligent data exploration not only enables organizations to take advantage of their data without waiting to hire more data scientists, it also plays a critical role in augmenting trust in AI solutions, fostering a more widespread, fair, and ethical use of AI. This increased trust will contribute to more responsible deployment and wider acceptance of AI solutions across various domains, positively impacting society as a whole.
By enhancing resource allocation, providing transparent and interpretable AI solutions, and developing user-friendly tools, intelligent exploration platforms like Virtualitics pave the way for wider AI adoption and for all organizations to reap the benefits of these transformative technologies. By leveraging XAI, Generative AI, and rich visualizations to guide users through the analysis of complex datasets, Virtualitics is creating a future where teams are prepared to make AI-guided data analysis not only attainable but a powerful ally.
About the author
Ciro Donalek is a leading expert in Artificial Intelligence and data visualization. As a Computational Staff Scientist at Caltech he successfully applied Machine Learning techniques to many different scientific fields, co-authoring over a hundred publications featured in major journals (e.g., Nature, Neural Networks, IEEE Big Data, Bioinformatics). He holds several patents in the fields of AI and 3D Data Visualization, co-authoring the ones that define the Virtualitics AI platform.
Dr. Donalek is passionate about teaching and public outreach and has given many invited talks around the world on Machine Learning, Immersive technologies and Ethical, Interpretable and Explainable AI. He holds a Ph.D. in Computational Sciences / Artificial Intelligence (University Federico II of Naples, Italy) and an MS in Computer Science (University of Salerno, Italy). He is married with two children.
Highlights momentum in emerging data analytics technologies and underscores foundational elements of intelligent exploration.
Pasadena, Calif., Sept. 7, 2023 – Virtualitics Inc., an artificial intelligence and data exploration company, today announced it has been recognized in eight Gartner® Hype Cycle™ reports. Gartner Hype Cycle reports provide a picture of the maturity and adoption of technologies across different functions, and how they are potentially relevant to solving real-world business problems and exploiting new opportunities. In the 2023 Gartner Hype Cycle, Virtualitics is recognized in eight reports, including:
- Hype Cycle for Data and Analytics Programs and Practices
- Hype Cycle for Analytics and Business Intelligence
- Hype Cycle for the Future of Enterprise Applications
- Hype Cycle for Data Science and Machine Learning
- Hype Cycle for Emerging Technologies
- Hype Cycle for Emerging Technologies in Finance
- Hype Cycle for Finance Analytics
- Hype Cycle for Human Services in Government
“Gaining recognition across eight Gartner Hype Cycles and in 3 separate categories, including graph analytics and multi experiential analytics, is an exceptional milestone,” said Virtualitics CEO Michael Amori. “We’re especially pleased to be being singled out in the Future of Enterprise Applications category. I see this as an important marker of our leadership in a new category of data analytics we’re creating, Intelligent Exploration.”
Intelligent Exploration uses out-of-the-box AI to bring advanced analytics within reach of business and data analysts, not just data scientists. Users can make queries in everyday language, explore extremely complex datasets, uncover critical insights, and generate multi-dimensional visualizations.
Virtualitics’ AI-driven analytics solution includes innovations at multiple phases of the Gartner Hype Cycle: graph analytics, multi experiential analytics including VR/AR collaboration, explainable AI, natural language query, data storytelling, and augmented analytics (enhanced by AI), among others. Together, these technologies form the foundation for Intelligent Exploration.
In the realm of finance, Intelligent Exploration is being used for customer segmentation and to explore and understand payments intelligence. Credit card issuers can detect and predict fraud risk factors using Virtualitics’ 3D network graph algorithm to visualize subtle, recurring patterns and define communities that humans can’t spot.
The Gartner Hype Cycle news follows Virtualitics’ August announcement of a $37 million Series C investment by Smith Point Capital and inclusion on the Inc. 5000 List of Fastest-Growing Private Companies in America. “If I had to use one word to characterize what we’re achieving and doing, it’s acceleration,” says Amori. “Both in terms of our growth as a company and in how we are accelerating informed strategic decision-making.”
To view a copy of the 2023 Gartner® Hype Cycle™ for Analytics and Business Intelligence visit www.virtualitics.com/hypecycle.
About Virtualitics
Virtualitics is pioneering Intelligent Data Exploration, delivering out-of-the-box artificial intelligence capabilities that make advanced analytics possible for more people and organizations. The Virtualitics AI Platform automatically discovers hidden patterns in complex, multi-dimensional data, delivering rich 3D visuals and immersive experiences that guide more informed decisions. Virtualitics helps public and private sector organizations gain real value from all of their data, accelerating their AI initiatives. The company’s patented technology is based on more than 10 years of research at the California Institute of Technology. For more, visit virtualitics.com.
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
Resources
- Gartner, Hype Cycle for Analytics and Business Intelligence, Edgar Macari, Peter Krensky, 27 July 2023
- Gartner, Hype Cycle for Data and Analytics Programs and Practices, Donna Medeiros, Andrew White, and 1 more, 26 July 2023
- Gartner, Hype Cycle for the Future of Enterprise Applications, Patrick Connaughton, Tad Travis, and 3 more, 18 July 2023
- Gartner, Hype Cycle for Data Science and Machine Learning, Peter Krensky, 27 July 2023
- Gartner, Hype Cycle for Emerging Technologies in Finance, Mark D. McDonald, 11 July 2023
- Gartner, Hype Cycle for Finance Analytics, Clement Christensen, 21 July 2023
- Gartner, Hype Cycle for Emerging Technologies, Arun Chandrasekaran, Melissa Davis, August 2023
- Gartner, Hype Cycle for Human Services in Government, Ben Kaner, August 2023
Generative AI tools like ChatGPT have emerged as potentially powerful assets for businesses across various industries. However, not everything created by generative AI has value, and some of it carries significant risks. The question is, what do users need to do to find strategic and safe uses for generative AI?
At the most basic level, generative AI is simply the ability to give AI a prompt and have it create new material. There are a lot of different kinds of AI, in addition to the large language models (LLMs) like ChatGPT that possess the ability to compose human-like text. These easily accessible tools are now being asked to create content ranging from resumes, to code, to poetry, to travel itineraries…with a lot of excitement, but varying degrees of success.
Organizations and individuals are recognizing the massive potential of generative AI, anxious to be among the first to benefit from the technology. But that enthusiasm has already introduced risk, such as the data leak from Samsung employees who were using ChatGPT and uploaded sensitive code. Instead, organizations are looking to develop their own internal generative AI or to work with companies that can deploy the technology for them safely. Companies that will be successful in using generative AI will need to make sure they do a few things right upfront if they want their AI to return meaningful strategic advantage, not just be a gimmick.
Define Clear Objectives
Before incorporating generative AI tools, it is crucial to establish clear objectives. Determine how you envision your organization benefiting from these tools and define specific potential use cases. For instance, you could enhance customer support, automate specific processes, or generate creative content. Defining your objectives will help guide you in selecting an AI tool or creating your own in alignment with your business goals.
Your first objective should be preventing generative AI from being an unnecessary veneer to brush up old systems. A basic dashboard that is “explained” by a tool like ChatGPT is still a basic dashboard with the same knowledge (or lack thereof) as ever. We are already seeing tools being marketed “…with ChatGPT” as generative AI success stories when the use of the tech isn’t actually providing deeper understanding or any other benefits.
Use your data to help you define your objectives. Projects that are currently “hot topics” or the personal favorite of leadership may or may not be good use cases for generative AI. It’s critical that everyone understands what the AI can do, what it cannot do, and where it can be most impactful. Your data can reveal real opportunities if you explore it diligently.
Require Robust Data Governance
Generative AI models like ChatGPT are only beneficial if they have substantial amounts of training data. It is vital to establish robust data governance practices to ensure safe and ethical usage of AI. An organization using an outside generative AI tool should be sure they truly understand the data sources and processes used to train the model.
Any system that accesses your data requires strong privacy and security measures to protect sensitive information. Transparency regarding data usage and obtaining the necessary consent from users are also essential steps toward maintaining trust and complying with privacy regulations.
Models Must Be Expertly Trained, Tuned, and Validated
Training generative AI models involves providing large datasets and fine-tuning them to meet specific requirements, all while exercising responsible AI practices. Training data needs to be monitored for biases, while also being checked for diverse representation so that biased data doesn’t perpetuate unfair or discriminatory content. Data scientists should continuously assess and update the model to improve its performance and address any unintended consequences.
Before deploying generative AI tools in real-world scenarios, it is crucial to conduct thorough quality assurance (QA) checks as well. Developers should have a comprehensive QA framework to assess the generated outputs for accuracy, relevance, and safety against established guidelines. Keeping humans in the loop when training AI models provides vital feedback on the system’s responses. Developers should refine the model based on the feedback received, enabling it to improve and deliver more reliable and valuable outputs over time.
Demand Transparent and Explainable AI
Generative AI tools, such as ChatGPT, can sometimes generate responses that are difficult to explain or comprehend. In fact, these models want so badly to provide a result to you that they may even hallucinate a completely inaccurate response. Organizations that expect to use generative AI to gain strategic advantages can only do that if their models include explainability.
Organizations should select or develop tools that incorporate techniques designed to help users understand how the AI system arrived at a particular response. Providing clear information about the limitations and capabilities of the system enhances trust and helps users make informed decisions.
Generative AI tools like ChatGPT hold immense potential for businesses seeking innovative ways to engage with customers, streamline operations, and foster creativity. However, unlocking this potential requires a diligent and cautious approach. By following these steps, companies can safely and successfully integrate generative AI tools into their operations. With careful planning, these tools can become valuable assets, empowering organizations to drive growth, innovation, and customer satisfaction in the era of AI.
Artificial Intelligence (AI) has been spreading across industries and growing in prominence and acceptance and the emergence of ChatGPT on the scene this year has launched the conversation into the stratosphere. ChatGPT has put a very public face on one of the most significant areas of progress, natural language processing (NLP). The intuitive interaction that happens in a conversational format allows the user to ask a simple question and, fueled by powerful processing algorithms, the NLP generates the answer. However, there are two major questions we have to ask ourselves: Can we trust the answers that AI engines generate, and how do we know that we can?
The validity of an AI-generated response depends on the type of question, the data being queried, the data that the AI has been trained on, and the complexity of the answer. Knowing when and how to use AI is a skill all its own, and it’s a critical one to develop if you want to use AI to leap ahead of the pack.
Deciphering the hype
The Gartner Hype Cycle identifies the phases in the life of a new technology. Right now, AI is sitting squarely atop the “Peak of Inflated Expectations” with tools like ChatGPT and Google Bard being touted as solutions for a massive variety of problems.
Those AI tools are a great solution…for some problems.
AI engines that are designed to operate on large data sets can process vast amounts of information in a short amount of time. This allows them to provide solid answers to straightforward questions, such as weather forecasts or sports scores, with a high degree of accuracy.
But a tool like ChatGPT doesn’t automatically give you the source of their information. You can—and should—ask yourself where those responses are coming from. When we do ask ChatGPT where it gets answers we get a fairly transparent explanation:
“As an AI language model, I have been trained on a vast amount of text data, including books, articles, and websites. My training data comes from various sources, such as news outlets, scientific journals, encyclopedias, and online forums. Additionally, I have access to real-time information through APIs, which allow me to retrieve data from various sources, such as news feeds, weather services, and stock market data. However, it’s important to note that I do not have personal experiences or emotions, and my responses are based solely on the information contained within my training data and the inputs I receive from users.”
Some of those sources, such as scientific journals and encyclopedias, are great. It would take us hours to search through that data on our own, making ChatGPT a powerful option for finding answers in those areas. But that information can be mixed in with other sources, like online forums, which makes the validity of the final result unpredictable.
The bottom line is that how, where, and when we use AI tools matters.
Creating transparent, trustworthy AI
When it comes to more complex questions that require an understanding of context, nuance, and human emotions, AI engines will struggle. We might ask a question like “What is the best way to motivate employees?” An AI engine could generate an answer based on data from studies and surveys, but that won’t tell us the whole story.
AI-generated answers also have significant room for bias and error because they are only as unbiased and accurate as the data they are trained on. (Remember how ChatGPT is accessing online forums? Yikes.) If the training data contains bias or is simply wrong, then the AI engine will generate wrong answers. We’ve already proven that this is a problem, as we’ve watched AI systems perpetuate systemic discrimination in hiring situations or lending operations because they were trained on biased data.
To address these shortcomings, data scientists are working to develop more robust and transparent AI systems. “Explainable AI” (XAI) algorithms provide a justification for the answer generated by the AI engine, allowing users to understand how the answer was reached and whether any biases were present.
Another approach is to use “human-in-the-loop” (HITL) systems, which combine the strengths of AI with human expertise. In HITL systems, the AI engine generates an answer, which is then reviewed and validated by a human expert. This approach can help ensure the accuracy of AI-generated answers while also reducing the potential for bias.
Developers are working to create all kinds of AI solutions. But are they solutions that companies need?
What users really want from Generative AI
Most companies are still trying to decide what they want and need in AI tools, but their first priority should be to select secure, transparent tools that bring real value to their organization. Sure, features like natural language query (NLQ) can feel like magic…but if the magic is just an illusion, or doesn’t help your business strategy, then what’s the point?
Combining technology helps us get more insight out of our dataset. For example, Knowledge Graphs are an incredible way to visually represent data and the communities and connections present, but exploring them has typically required someone who could write sophisticated queries. But if you were to combine a Knowledge Graph with a Large Language Model (LLM) then you would have the ability to ask a question and explore that data visually, no code required.
Companies should be looking to empower data analysts to do far more than they can with BI tools that were never designed to explore complex data. Knowledge Graphs and Natural Language Queries are just two of the many possibilities delivered in the Virtualitics AI Platform. Our focus is on Intelligent Exploration: using AI to find insight and guide analysts as they explore their data. With the right advanced analytics tools, organizations can put data science capabilities in the hands of their analysts so they are empowered to discover opportunities, do deep analysis, and get stakeholder buy-in.
Are you ready to level up your data analysts and put AI to work? Schedule a 1:1 demonstration with our team.

New Podcast Episode:
People, Processes, and Technology
On our latest podcast episode, Caitlin Bigsby, Virtualitics’ Head of Product Marketing sits down with Shreshth Sharma, Senior Director of Strategy and Operations at Twilio, to talk about his journey into the world of data and analytics from management consulting. Drawn by the intersection of business, technology, and data analytics, Shreshth has built a great reputation in analytics—we appreciate him sharing his unique perspective with us.
Listen on any of the following podcast platforms.

New Podcast Episode:
Speaking the Same Language of AI
On our latest podcast episode, Caitlin Bigsby, Virtualitics’ Head of Product Marketing sits down with Justin Smith, Ph.D. on the power of exploring our data with an open mind. Listen to our podcast to hear Justin share his background in Neuroscience, his transition into data analytics, and how exploring data is empowering entire organizations to gain the competitive advantages they’re looking for.
Listen on any of the following podcast platforms.
It’s a new year and with that comes a clean slate and the best of intentions to get things right! If you have “Build a Successful AI Program” at the top of your 2023 resolution list then here are 5 things that you need to embrace.
1. Rediscover the Lost Art of Data Exploration–This Time with AI
Many AI use cases will fail from a lack of appropriate data exploration early on in the process. The old tools that are in use for basic analytics, while still useful, are not getting the job done for exploring the vast data that are relevant for AI use cases. And considering that AI is intended to automate decision-making and action-taking at scale, making sure that you’re pursuing the right use case and using the right data sets is critical.
In 2023, don’t try to validate hypotheses using basic BI to justify your next AI use case. Instead, leverage AI algorithms to explore business challenges with an open mind. This will bring more options, reduce bias, and ensure that you’re following up on high-impact possibilities. To learn more, read What is Intelligent Exploration?
2. Finally(!) Start Using Modern Data Visualizations
Fully interactive multidimensional visualizations are the next standard in advanced data analytics. They are game-changers for both front-end exploration of data and for illustrating the findings and implications of your AI algorithms. Analysts and data scientists that try to show complex data relationships in traditional business intelligence tool visualizations will fail to communicate them clearly, they won’t get informed buy-in, and they could actually lead organizations down the wrong path.
AI-generated true 3D visualizations make the relationships between multiple data points consumable. Instead of a rabbit hole involving the comparison of myriad pie charts, histograms, and scatter plots, true 3D illustrates the connections concisely. We’re not talking about forced-perspective 3D, either. We’re talking about visualizations that can be manipulated like an object in space, rotated by the observer, and pulled in to zero in on a particular point. We’re talking about native 3D visualizations. To create better AI, you need more data; to find the insights in more data, you need more robust visualizations.
3. All Things Network Graph
Gartner analyst Rita Sallam said the research and advisory firm forecasts that 80% of data and analytics innovations will be made using graph technology by 2025 and the market is expected to grow by 28%. But most heads of Analytics have only a passing familiarity with network graphs and how they can be used at the Enterprise level. It’s no surprise, really. The tech stack and methodology have been complex, meaning that most data professionals just don’t have any experience.
So for 2023 your goal should be to learn more about what network graphs can do, because they’re more accessible than ever before with AI-powered Network Extractors. Now teams are able to create persona profiles of high-churn customers, spot the weak spots in a supply chain, and analyze any highly connected datasets. Read more in our Beginner’s Guide to Network Analysis.
4. Find Beauty in Simplicity
We were all blown away by the capabilities of GPT-3 (an advanced AI-powered search, conversation, text completion app) and perhaps dream of unveiling something that vast and ambitious ourselves. But for 2023, let’s take a moment to appreciate the beauty of a simple solution. Just because AI is the mission doesn’t mean that AI is always the answer. With just over half of AI projects getting to production, it’s pretty clear that we could be doing a better job vetting the use case list.
The ability to spot the best, most effective path forward is where robust exploration in the preliminary project phases really pays off. Once you’ve surfaced your potential use cases, look at possible solutions from all angles, and include business stakeholders who will have a different perspective. When considering feasibility, don’t forget to count technical costs, and change management costs, alongside everything else. And if you come to the conclusion that the best solution is not an AI model? That’s a win, proof of the team’s value, and shows you have a thoughtful assessment process. Read more about Finding the Right AI Use Case.
5. Responsible AI Means Ownership of the Model
Much is said about responsible AI–AI that is transparent in its predictions and is thoughtfully developed to account for bias and downstream impact. But nothing can be truly responsible without accountability. Frustratingly, once deployed, AI models seem to become orphaned, with no one taking ownership. If something goes wrong in production, where does the buck stop? And if no one is responsible once the model is applied, who feels the responsibility during the development process to make sure that the model itself is responsible?
Data and Analytics leaders should consider clearly defining roles and responsibilities for all AI projects for the business. These responsibilities should include providing the business with clear information about what data is being used, how it is being used, and the impact the model had during testing in a format that business stakeholders can understand. It is the responsibility of the business stakeholders to consume this information and ensure that they understand it. A plan for remediation should be in place should the model drift or not perform as expected and someone should be named to monitor the model. Furthermore, users should be empowered to understand the model, and understand when they should challenge the model’s results.
Are you ready to make Intelligent Exploration, 3D visualizations, and AI part of your 2023 game plan? Contact us for a personalized demonstration.
Multitasking? Great! You can listen to this blog post by clicking above or find our podcast, Intelligent Data Exploration, on major podcast platforms.
As the Head of Product marketing at Virtualitics, I am always curious about how data scientists explore their data before deciding how, or even whether, to tackle an AI project. Understanding data quality, outliers, and whether you’re targeting the right problem before you start down the road to model development is a really important first step.
A couple of weeks ago I took to LinkedIn to get some answers. I posed a simple question in a couple of data science groups I belong to asking data scientists how they learn more about the nuances in their dataset before embarking on an AI project. The options were: Explore the data in Excel; Explore with visualization tools, Explore with a Python tech stack, and Leverage past experience.
The combined results (out of 1113 responses) looks like this:

While a sizable number of people are still leveraging Excel to do exploration, visualization tools are the clear leader, followed by Python.
The reliance on Python is no surprise–as datasets get increasingly complex, data scientists need code, AI, or some form of computer assistance to figure out where they ought to be looking. But visualizations are still absolutely critical to bring clarity to the exploration.
The challenge for a lot of data scientists is that they have to choose between the two approaches and there are drawbacks to both. Relying on traditional BI & visualization tools means doing more simple analysis of subsets of data and then trying to knit together a conclusion.
Using a Python tech stack means firstly having a comfort level with the code and knowing that you’re using the right algorithms to explore. Then it’s selecting which insights to illustrate for discussion. But illustrating all of the AI’s findings to fully interrogate the insight is still out of reach. Additionally, finding the right means of communicating these insights to non-technical stakeholders without introducing confusion is still required.
At Virtualitics, we’re bringing those two elements together so that data scientists do not have to compromise between those two options. We’ve built an AI platform around what we call Intelligent Exploration–AI-driven, AI-guided, and AI-visualized exploration of vast, complex datasets.
Data scientists get the benefit of an AI co-analyst to help them uncover and explore complex data insight visualized in next-generation, true 3D visualizations that clearly illustrate the complex relationships discovered by the AI. This out of the box capability also puts data science power into the hands of data analysts. They can do some of the preliminary work, leveraging AI-generated insights to draw attention to areas of significance so nothing gets overlooked and relieving some of the pressure on overburdened data science teams.
At Virtualitics, we believe that the Explore step is critical to the success of any AI and advanced analytics project. We’re helping you explore without limits.
Download our e-book Building a Sustainable AI Strategy from the Ground Up advanced to learn more about how you can use Virtualitics to power your AI and Data strategies.
Multitasking? Great! You can listen to this blog post by clicking above or find our podcast, Intelligent Data Exploration, on major podcast platforms.
AI is on the brink of becoming mainstream, but many organizations aren’t even attempting to use AI yet. Where does your team fall on that spectrum?
No matter where you are on the AI maturity curve—just getting started or preparing to dive deeper—our experience has shown that there are nine steps to creating a successful AI strategy.
Those nine steps can be divided into three parts.
Part I: Explore & prepare
- Explore
- Identify & refine
- Define
- Prepare
Part II: Develop
- Test & monitor
- Model Selection
Part III: Deploy
- Deploy
- Adopt
- Assess
Getting started on the journey to making AI an embedded part of your business’s strategy is easier than you think. Let’s look closer at each step to see how you could be building your AI strategy.
Part I: Explore & Prepare
1. Explore
Thorough data exploration is the foundation of every choice, strategy, and initiative that your business takes on. You owe it to your teams and your stakeholders to make sure you understand the insight in your data before taking action.
Full data exploration allows us to understand the real challenges in our business, as well as how multifaceted those challenges are. Exploration leads teams to see the connections between data and the drivers influencing their business.
If you don’t have the resources or experience on your team to explore your data thoroughly with traditional BI tools then it’s time to get better tools. Virtualitics’ Intelligent Exploration uses AI to explore all the relevant data across more dimensions, without bias, and surface explainable insight.

2. Identify + Refine
This next phase builds on the foundation that you built in Explore, digging in to identify key drivers and refine your insights. This step includes:
- Reviewing and prioritizing findings with subject matter experts and stakeholders
- Creating a prioritized shortlist of the possible issues to address, considering both the level of effort and level of impact
- Determining the appropriate solution for the highest priority issues
A solution should also be tailored to the problem. While AI is ideally suited to search through your data to find root causes, it can also forecast possible scenarios and discover patterns in data that will help you select the best solution for each issue. The logical next steps could also include reports, dashboards, or process changes that help teams manage the problem you’re focusing on.
3. Define
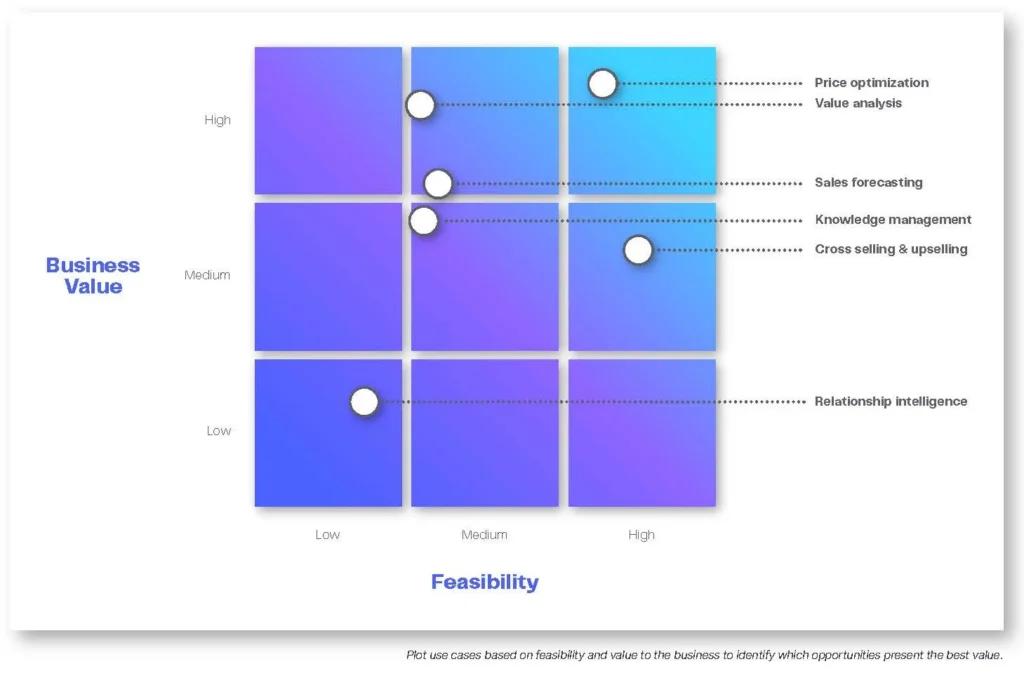
Exploring data before identifying and refining potential solutions means that your project definition phase is focused on the right opportunity. With the information already learned, teams go into project scope definition with a clear view of the drivers, outliers, and trends in their data that are impacting the challenge they want to address.
Project definition is all about defining what your solution is, how you’re going to build it, what deployment will involve, and what you expect the business impact to be. Impacts will hopefully be mostly positive, like increased productivity, but you must also consider the effort and expense of process changes and adoption.
You’ll need to prepare a business case that defines the scope and value of the effort, and gets executive buy-in. Your business plan might include visuals like network graphs, projections, definitions of success, and a clear schedule of next steps. If your solution includes an AI model, you’ll also define the targets and evaluation metrics for your model. Virtualitics’ Intelligent Exploration automatically identifies good targets for AI modeling and provides appropriate evaluation metrics for KPIs, so teams can clearly identify how they will measure the success of their efforts.
You may get through this point and determine that the cost of moving forward with any change is not worth the impact that it will have on the problem. That does not mean that you failed! In fact, it shows the value of the process that you have learned enough to know not to waste resources on something of little to no value.
4. Prepare
If your solution includes an AI model or a dashboard, you’ll need to prepare your data so that it’s ready to be fed in. The more you can automate loading data, the more frequently you can refresh your data—frequent updates ensure that your model or dashboard is leveraging the most current data. Because data typically comes from multiple sources it is also likely to be in different formats that need to be reconciled to work together.
Part II: Develop
If you are moving forward with an AI project, part II of the process is actually developing the model based on all of the groundwork that you’ve done up to this point.
5. Model Selection
To be truly effective, AI models need to be able to grow with your business. Iteration is a vital part of selecting the right model for deployment.
Selecting and developing models is based on the problem to be solved and the data available. Teams may need to deal with issues like missing values, anomalies, and other data-cleansing activities. Data scientists who understand their datasets can choose models that can deal with missing values, or clean the data prior to incorporating it into the model. Iteration is also necessary to select the best model, which is much easier to accomplish with AI to help.
6. Test and Monitor
Once a model is deployed it must be monitored and validated. That includes backtesting, checking out-of-sample data, and investigating forecasts from the model by comparing it to a trusted benchmark.
The remaining steps are applicable to both AI and non-AI solutions.
Part III: Deploy
Having taken the necessary steps to create a solution that’s solving a real business problem, and with the buy-in from stakeholders, you can deploy your solution with confidence.
7. Deploy
Deploying a solution means getting your solution into the hands of the people who will use it. This process will vary depending on the nature of the solution but should include champions in the business and in IT solutions who can help teams successfully put the solution into practice.
8. Adopt
The benefits of a strategic solution cannot be realized if the solution isn’t adopted by the applicable users. Adoption best practices include:
- Explaining how the solution will have a positive impact at all levels of the organization
- When and how the solution should be used
- How you’ll monitor the solution
- How you’ll measure the success of the solution
You can help build confidence in solutions by including visuals that explain how the AI works in a way that is easily understood by all end-users.
9. Assess
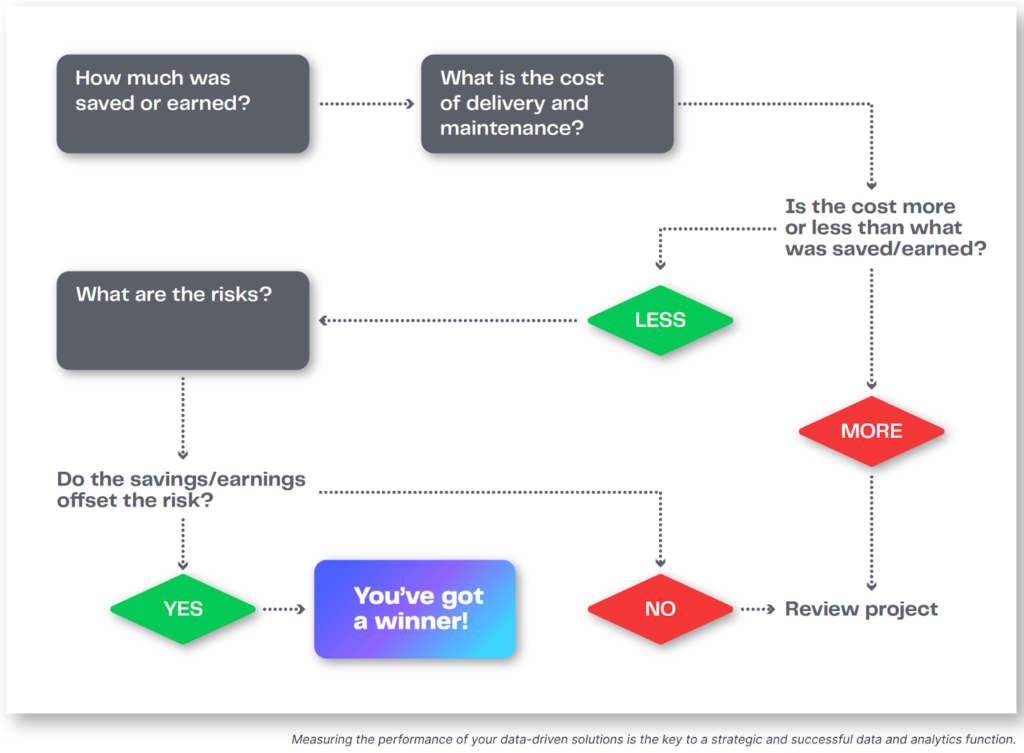
A solution needs to be measurable, so teams know if and how they should adjust it. Key performance indicators and other metrics like financials, technical cost, and risk level can also be used to determine success and validate next steps.
Building a Successful AI Strategy
When teams follow these steps, building on a strategy of exploration and insight, they can create a sustainable AI strategy that will support business transformation and growth. They can confidently promote innovation, define solutions, and monitor them for success. For more details on these steps, you can download our e-book Building a Sustainable AI Strategy from the Ground Up.
When my co-founders, Ciro Donalek, Prof. George Djorgovski and Scott Davidoff, and I founded Virtualitics in 2016 after 10 years of research done at Caltech, we did so with the ultimate vision of helping people better understand and drive value from their complex data.
We knew that making advanced analytics more accessible and easier to understand would lead to better AI, better decision making, and ultimately help people solve the previously unsolvable.
Over the past six years, we have seen Virtualitics transform how companies make decisions, whether it be supporting predictive maintenance for the US Air Force, enabling researchers to speed up the pace of drug discovery, or helping financial institutions more efficiently manage risk.
While it’s incredibly rewarding to see Virtualitics being used by companies today, what’s even more inspiring is the potential of how it will be used in the future. That’s why it was incredibly exciting to learn that Virtualitics was Recognized by Gartner, the world’s leading research firm, as a 2022 Cool Vendor for Analytics and Data Science (I may have let out a ‘whoop’ when I got the news.) To be included in this report is no small accomplishment. It means that your company is anticipating where the market is heading and delivering a solution that drives real business value.
Why cool?
Virtualitics was one of only three companies selected for this year’s Gartner® Cool Vendors in Analytics and Data Science. Here are a few of our capabilities Gartner® singles out:
- An immersive platform that brings a bit of the experience of real-time gaming to analytics. Like a shared virtual reality (VR) office where users can stand inside of and touch a dataset.
- Ability to combine up to ten dimensions of data versus two, and deliver complex analyses of them in visually compelling ways.
- A workflow experience that moves users seamlessly from discovery to analysis to action. Teams can collaborate from anywhere, including mobile devices, visualize what lots of complex data is saying, then act on it, right in the dashboard.
- No coding skills required.
Closing the Gap between Data Science and the Business
All of these capabilities are in support of our larger mission, closing the gap between data science and the business. At every step of the analytics process, from preprocessing, to data exploration, to AI predictive models Virtualitics enhances the user’s ability to understand what is happening. Whether the user is a data scientist, data analyst, citizen data scientist, or a business stakeholder we ensure that the insights are pulled forward for you to see, touch, and explore.
Realizing the Potential of AI
Why does closing the gap matter so much? Because for organizations to realize the potential of AI and scale it across their enterprise in the form of AI applications that inform decisions and direct actions, it first needs to be the right application and the right AI model. That means that the investigation needs to include the business so that they can provide background and expertise, and identify where AI can be best leveraged. And it means that the exploration underlying the AI model needs to be comprehensive–something that can often take months using traditional methods.
It also means building trust with the users who are expected to act on the AI models. The last mile of AI delivery is the hardest to bridge, and we’re gratified that Gartner has acknowledged that we’ve done it.
If you’re interested in reading more, you can download the full Gartner 2022 Cool Vendors in Analytics and Data Science here.
