

Data analytics teams are often overtasked and understaffed. To keep delivering results, they are oftentimes forced to take shortcuts or significantly reduce the scope of their analysis. This is especially true when it comes to dealing with large, complex datasets. Data sampling can provide relief for analysts, but it also introduces new challenges.
What is Data Sampling?
Data sampling is the process of selecting a subset of data from a larger dataset. There are many reasons why sampling can be beneficial, but the primary purpose of sampling is to reduce the size of the dataset being analyzed, which, when done correctly, can save time, reduce costs, and make it easier to identify insights within the data.
Sampling is particularly useful when dealing with big data, which is often too large to be processed or analyzed in its entirety. By selecting a smaller subset of the data for analysis, data scientists can still draw conclusions and then evaluate whether or not they apply to the entire dataset without having to analyze every single data point.
It might sound simple, but a poorly chosen sample can cause a myriad of problems and lead teams to incorrect conclusions.
Why is Data Sampling Difficult?
Selecting a sample is not always straightforward, and can be influenced by a range of factors including the size, variability, and data types present in the original dataset along with the sampling algorithm used. Oftentimes, data analysts have a tendency to just pull the first “N” rows and analyze those, but that can be dangerous if the initial rows of data don’t match the distribution of the rest of the dataset.
Selecting a sample isn’t just about reducing the scope of your data exploration—many would say that the goal of sampling data is to select a subset of data that is representative of the entire population so accurate conclusions can be made about the population as a whole. However, there are hundreds, if not thousands, of different statistical tests, each with their own strengths, weaknesses, and assumptions that have their own ways of defining whether or not a sample is truly representative. All of these facts lead us to the question: How should our customers effectively sample data, and how can we make that method practical and accessible for data analysts?
Virtualitics’ Smart Sampling
At the beginning of our product development journey for smart sampling, our goal was to create a generalized algorithm that would effectively generate samples from massive datasets at scale by leveraging distributed compute frameworks like Spark.
However, before we could dive into the actual algorithm development we first needed to define what would make a sample “better” than another sample. Inherently, this is a very difficult thing to define in a general way because in reality, the reasons a sample might be “better” than another sample could vary greatly across data sets and use cases. As a result, we started our process by sifting through hundreds of papers from a variety of disciplines that pertained to creating samples. Our research included Spatially Balanced Sampling through the Pivotal Method, Finding Representative Set from Massive Data and Sublinear Algorithms for Outlier Detection and Generalized Closeness Testing. From studying the work done in these publications and others, we were able to narrow our focus to a few key metrics for evaluating the “goodness” of a sample of data.
In parallel, we were also able to collaborate with our stellar Scientific Advisory Board (SAB). Each member of this unique board provides our team with insightful perspectives based on their own areas of expertise and their knowledge and guidance is an invaluable resource for us. We also solicited feedback and input from the commercial space by speaking with senior data scientists at a variety of leading companies, including those in the Fortune 100. By combining their advice with that of our SAB and the literature we studied, we confirmed our suspicions that there’s no such thing as the “perfect” or “best” data sample.
We realized that the goal of Smart Sampling should be to design generalized algorithms that can process large datasets at scale and then suggest interesting and insightful samples of data for downstream analysis.
We started our algorithm development process by first considering a variety of datasets to come up with test cases and scenarios to work through. This was really helpful in making sure we covered a wide range of sampling use cases and that our algorithms would be performant in many different scenarios and data distributions. During this process, we recognized some fundamental truths when it comes to data sampling:
- Anytime you are sampling data there is always a risk that you might miss something important in your sample, or that your sample doesn’t have exactly the same relationships that are present in the original data.
- Anytime you are sampling data, regardless of the method you choose, the resulting sample will be different from the original data set. This means that the sample will introduce some biases that were not present in the original data set.
- Evaluating a sample can be a fairly subjective process depending on the overall objectives of the data scientist or analyst extracting the sample.
Recognizing that sampling data brings inherent bias and introduces risk, we set out to provide options and methods that would empower data analysts by providing smarter, more effective choices in creating data samples. Our solution maintains ease of use while still providing users with fine-tuned control–putting data analysts in the driver’s seat with a powerful selection of algorithms to help them select appropriate data samples.
Smart Sampling Means Having Options
In Spatial Sampling (one of our proprietary smart sampling algorithms), we focused on trying to generate samples that spatially spanned the range of the parent dataset. We accomplished this by developing a novel clustering-based sampling approach for which a patent application has been filed.
In our Validation Based Sampling algorithm we took a different approach. Here, we focused on trying to capture relationships in our sample similar to those present in the original data. In order to do so, we actually leveraged two other proprietary Virtualitics AI routines: Smart Mapping and Anomaly Detection to make sure that generated samples had both similar relationships present and a similar number of anomalies as the original dataset.
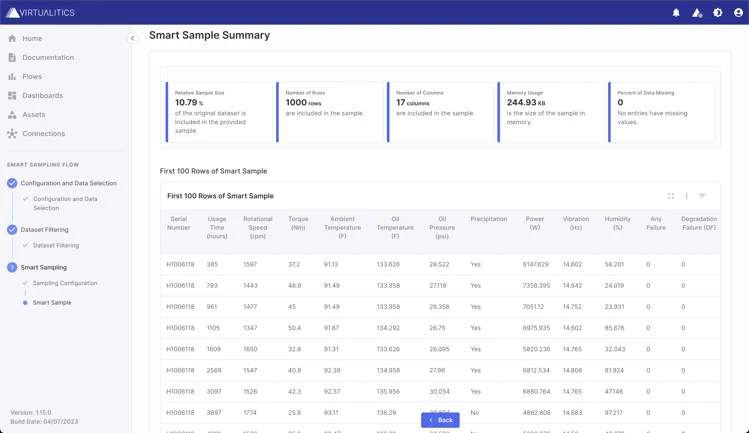
In addition to these algorithms, we also have an implementation of random sampling that works both on distributed compute clusters as well as “locally”, on our deployed worker. Although it is simple and straightforward, random sampling is a versatile algorithm that can and should be used in specific scenarios.
Overall, it’s been very rewarding to see Smart Sampling in action. We have enabled data analysts and scientists to easily generate samples of their data for further analysis, without having to write a single line of code. Even though it hasn’t been “live” for long, it’s already been an empowering tool that has enabled practitioners to really take advantage of data that would oftentimes otherwise go ignored.
Smart Sampling is a critical step in our Intelligent Exploration process. To learn more about how Virtualitics can level up your data analysts—including managing the scope and effort of their exploration using Smart Sampling—set up a 1:1 demonstration with our team.





