

In the last post from our AI: From Models to Missions series, Virtualitics VP of Product Aakash Indurkhya explored the challenge of turning massive amounts of data into actionable insights for the DoD—and how conversational chat interfaces and AI agents can bridge that gap, making critical information more accessible and understandable for decision makers.
Even with clear, relevant insights in hand, a monumental task remains for decision makers: turning this knowledge into action.
This isn’t just extra work, it’s a chasm. Finding the insight is the increasingly easy part—the real challenge lies in overcoming the inertia, resistance, and friction that prevents it from becoming an impactful action.
In any organization—and especially in the multi-layered, chain-of-command-based Department of Defense (DoD)—every insight and recommendation must be influenced up the decision chain.
Challenges in the Decision Chain
In the DoD, insights and recommendations often pass through seven or more layers of hierarchy before a decision is made—a journey involving multiple stakeholders, each with their own role in advancing and finalizing the decision. And sometimes, even lateral decision gatekeeping adds more links to the chain.
The result? An enormous game of telephone, where even well-founded insights can get diluted, reinterpreted, or lost entirely before they reach the final decision maker.
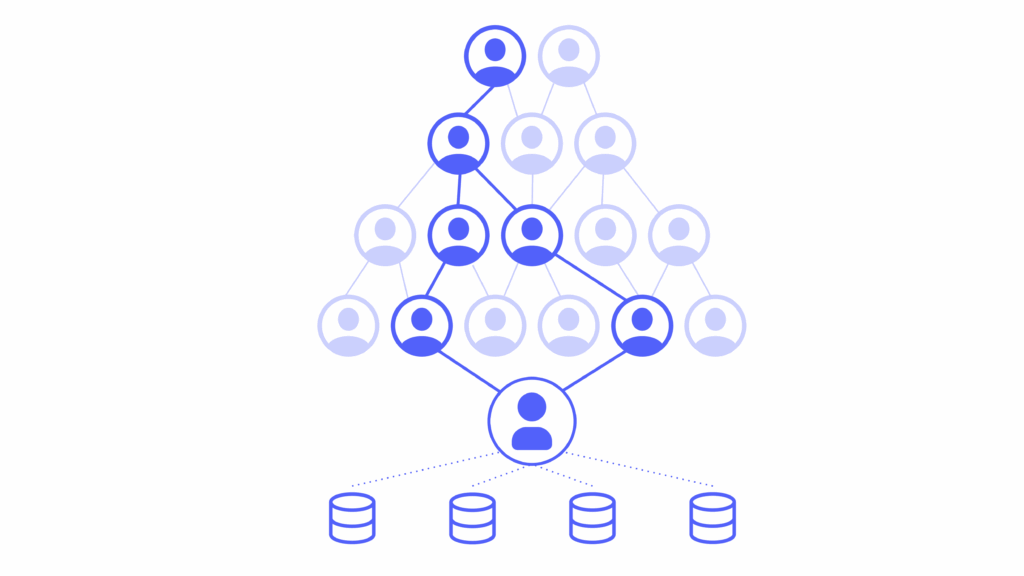
Communication breakdowns are common: an insight may be unclear to the next link in the chain, misaligned with their broader worldview, or incompatible with how they frame the problem. And delays aren’t always due to misunderstanding—sometimes they’re the result of legitimate pushback.
Different leaders bring different expertise and perspectives, requiring deeper conversations and more evidence before moving forward. As decisions move higher up, senior leaders gain visibility into broader strategic, economic, and political considerations that can override or reshape the original recommendation.
For example, the GAO estimates the F-35 Lightning II Joint Strike Fighter program’s lifetime cost at over $1.7 trillion. While sustainment-level teams may focus on near-term maintenance priorities, senior leaders must also weigh long-term costs, political implications, and economic trade-offs—factors that inevitably influence the final decision.
This is why data alone often isn’t enough to close the chasm between insight and action. Stakeholders feel strong ownership over their domains, making influence a dominant factor in decision making. If AI can’t help humans navigate that influence dynamic, its impact will be neutralized.
Removing Friction with AI
Recent advances in AI are shifting what’s possible. Large language models (LLMs) move analytics into a universal medium: conversation. By using natural language, users can refine their arguments early, ensuring the right talking points and insights are ready for each discussion.
What was once purely a human skill—navigating the politics and nuances of the decision chain—can now be supported and accelerated by AI.
Once a user submits a natural language query, AI agents can parse it, each with a specific role: retrieving data from key systems, applying filters, manipulating datasets, or producing tailored outputs. Furthermore, multiple AI agents that are attuned for readiness can account for different stakeholders’ perspectives and priorities, then interact with each other to mirror the back-and-forth that happens in the decision chain.
By surfacing potential objections, aligning on shared priorities, and highlighting the most critical insights for each audience, these agents help users “play the game of telephone” more effectively—ensuring the message arrives intact and persuasive. This collaborative, context-aware approach lays the foundation for a new paradigm in data-driven decision-making.
This process works best when AI agents have the right context—knowing the user’s role, organization, and history—and when LLMs are fine-tuned to anticipate how insights should be framed and supported so they can pass smoothly through the chain.
Just as stakeholders give feedback on recommendations, users can provide feedback to AI agents, guiding them to improve over time. This process, known as Reinforcement Learning from Human Feedback (RLHF), uses that feedback as a reward signal to align LLMs with human preferences—helping them course correct and deliver more effective responses in future queries.
Building Trust in AI Agents
Leveraging autonomous AI agents to influence critical decisions challenges the way defense decisions are traditionally made—with humans in the loop at every step. As the number of agents grows, so too do concerns about overstepping boundaries or errors going unnoticed for too long.
Addressing this starts with a clear operating protocol: a shared set of rules for how AI agents interact with each other and with readiness analytics tools across the DoD.
Additionally, a governance class of AI agents—focused solely on enforcing chain-of-command and maintaining organizational integrity—should act as an oversight layer between AI processes and the user interface. These governance agents can flag questionable insights or deviations from established patterns, prompting human review when necessary.
With clear governance and human feedback in place, humans remain essential participants in decision-making, even as AI strengthens the links in the chain. Done right, this human-AI partnership can significantly reduce decision cycle time while preserving accountability.
Closing the Loop
By enabling AI to address not just the data, but also the human factors that shape decisions, we can bridge the chasm between insight and action. This is a chance for AI to enhance not only what is known, but how it is communicated and acted upon—turning the game of telephone into a game of precision.
In the next blog in this series, we’ll explore how Virtualitics improves insight consumption and decision influence, while ensuring governance keeps the chain-of-command intact, departmental boundaries respected, and humans firmly in the loop.





